Computational Robotics
A journey into the cognitive side of how robots work with Raspberry Pis, hacked Neato Vacuum cleaners, and Laptops armed with Ubuntu, Python, and ROS, this first revision of the class has been a real challenge.
|
Project 0: The Warmup Project
The goal of this project was to get a Neato vacuum cleaner to perform a simple wall-following behavior given the ROS toolkit and the onboard laser scanner. The video shown demonstrates the robot moving in the robot simulator, Gazebo, based on the autonomous behavior programmed in the robot. Github code here (includes report pdf) |
|
|
Project 1: The Particle Filter
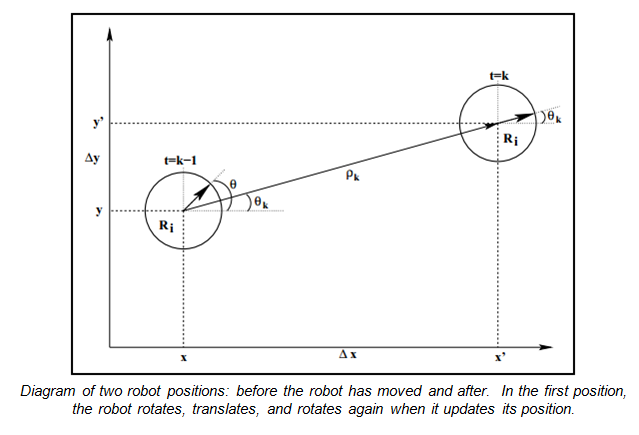
In this project we were tasked with building a particle filter in order to help find the location of the robot in a 2D map of the physical world. It's an example of probablistic robotics, which combines noisy sensors with mathematical constructs such as Bayes' Rule. The problem we’re tackling here is localization of the robot in a known map that has a wide variety of possibilities (large areas) or a map with similar features (therefore high in global uncertainty). From a technical standpoint, the particle filter uses the Bayes’ theorem and approximates its posteriors by taking a random distribution of a finite number of samples and updates based on the last known position. Basically the Bayes rule is used to estimate the state of a dynamic system by looking at sensor measurements. Bayes filters assume that past and future data are conditionally independent if you know the current state-- assuming you have a Markov environment. The particle filter is a type of algorithm based off of the Markov chain Monte Carlo (MCMC) methods, which was developed by the team of physicists working on mathematical physics and the atomic bomb during World War II. The MCMC methods attempt to solve a problem by taking in a bunch of random numbers and mapping those to some set of outputs in order to generate a solution. Although the method has been around since the late 1940s, it was not widely used until the 1990s-- in fact, the term “particle filter” dates back to 1997. The application of the algorithm to robotics is just about as old as the students in the class! In our specific representation, there are a few key elements. The particle filter has three frames of reference: the base frame, the map frame, and the odometry frame. The base frame is the frame relative to the robot, the map frame is the global view of the world that includes the robot, and the odometry frame is the frame relative to the wheels or odometry sensors (encoders) that is how the robot thinks where it is. Our particles consist of tuples (x,y, theta, weight), where x,y, and theta are coordinates of our hypotheses relative to the map frame. We first initialize the cloud of particles, see if we’ve passed our distance threshold, then update our probabilities based on odometry data, then laser scan data, then re-sample the particles and update the robot’s position from there. The resampling step picks particles with greater likelihoods more frequently than the other 300 particles, which results in a fewer number of visible particles as the robot gets driven around the map. Github code here (includes lab report in pdf) |
|
Project 2: The Vision Project
|
We detected faces in the video feed from the laptop webcam by running OpenCV’s built-in Haar Cascade face detector algorithm. We then cropped the image to focus solely on the region of the person’s face and ran a smile detector to determine if the person was smiling or not. If the person was smiling, we had the neato drive toward the person. If they were not, the neato would slowly back up.
Open CV’s Haar Cascade algorithm (aka. the Viola-Jones Method) is based on Haar-like features, which are digital image features used in object recognition. Haar features look at adjacent rectangular regions of an image, sum the pixel intensities in each region, and calculate the difference between these sums in order to categorize subsections of an image. For example, an image of a face will show that the region of the eyes is darker than the region of the cheeks, so a common haar feature would be the two adjacent angles that lie above the eye and the cheek region, whose position is defined relative to a bounding box that encloses the target object, or face, in this case. Generally the system runs through a progression of loops that go from coarse to fine feature detection, and runs, or cascades, through images quickly if it doesn’t find a face. People’s faces have easily identifiable features, such as the nose, eyes, forehead, chin, and mouth, so a color image of the face can be converted to greyscale and then this image can be overlaid with rectangles that enclose these areas. There were cascade data sets for the Haar Cascades algorithm that existed in OpenCV, however, we couldn’t determine the parameters for detecting smiles and went to build our own smile detector instead that took advantage of machine learning principles by using logistic regression. Github Repo with lab report |
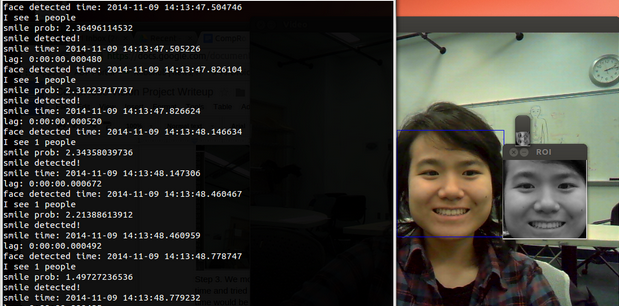
This shows the basic facial and smile detection algorithm. The color image from the webcam is converted into black and white and our logistic regression method focuses on the mouth region to see if there is a smile detected or not.
|
|
Project 3: Final Project: WALL-E
In order to make WALL-E more future-proof, we turned it into a platform capable of using the ROS framework and OpenNI (open-source Kinect software) in order to accomplish a robust robotic system that could interact with you. For more details on WALL-E, see my other page here. In order for robots to become more integrated into our daily lives, we must be able to have more natural interactions with them. More natural forms of communication involve both explicit and implicit communication. Explicit communication is limited to specific environments, and implicit communication can add clairty, contextual input, and efficiency. If robots were able to partner with humans as effectively as dogs do with their handlers, the social and technical roadblocks to having human-robot teaming and collaboration would be reduced. Intuitively, we are all predispositioned towards nonverbal cues, as we can easily intuit others emotional states through discussions and personal interactions. Gestures also replace speech when we cannot or do not want to verbalize our thoughts and help regulate the back-and-forth flow of speech in a conversation. Robots will need to be able to interact with a lay audience which will not necessarily be used to interacting with a robot through a computer and a screen, but are generally more familiar with cues such as pointing in a specific direction or waving. Link to Github repo with lab report |
|
